
Compact, programmable, ultra-low-energy programmable architecture for real-time signal processing, mid 2025 version comprises RISC SERV.
- Project Title : Programmable Stream Processord
- CEA partner(s) : LETS
- External partners : CentraleSupelec Geeps
- Financements : CFR
- Date de début : 2023
- Status : PhD in progress, first papers and results
Keywords : Program processors, Single instruction multiple data, Memory architecture,Signal processing, Energy efficiency, Silicon,Electronic circuits
In many signal-processing systems, energy is not spent on arithmetic – it is spent moving data. For constrained domains (cryogenic quantum control, biomedical implants, embedded radar), memory accesses dominate power, and the usual tricks (bigger caches, locality tuning, complex memory hierarchies) either do not fit the area budget or do not scale. Our core hypothesis is simple: if we can process samples immediately as they arrive, we can eliminate most memory traffic and shrink control overhead.
Process streams on-the-fly with no memory, while keeping programmability by using a tiny RISC-V core array driven by a centralized stream controller.
What ‘memoryless’ means:
- no data memory (no stack, no heap, no load/store to SRAM/DRAM);
- samples arrive as streams and are immediately routed to compute cores;
- temporary values live only in registers (a shared register file acts as a short-lived buffer, not a programmable memory);
- the system is organized as tiles; tiles can be chained to build complete pipelines.
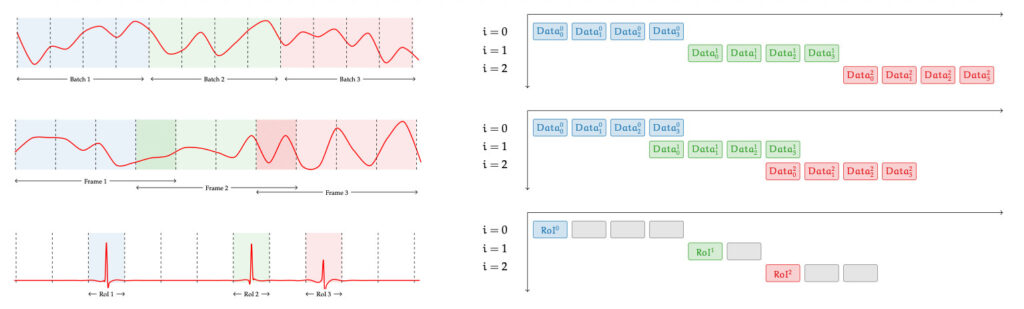
Streaming patterns we target
From profiling common DSP pipelines, we identified three dominant modes of operation:
- RoI (Region of Interest): process only detected events (e.g., pulses).
- Batch: consecutive blocks (e.g., FFT / block transforms)
- Convolutional: sliding/overlapping windows (e.g., FIR-style processing).
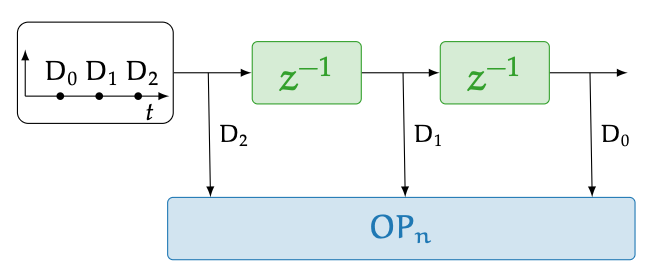
How execution stays efficient: Delayed-SIMD (D-SIMD)
Classic SIMD assumes all lanes receive aligned operands at the same time. Streaming acquisition breaks that assumption. We introduce Delayed-SIMD: one instruction stream is shared across cores, while small hardware delay elements align staggered data so that each core executes the same instruction on the right sample at the right time.
This keeps the simplicity of SIMD (single fetch/decode, broadcast execute) but adapts naturally to real-time streams.
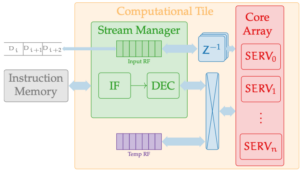
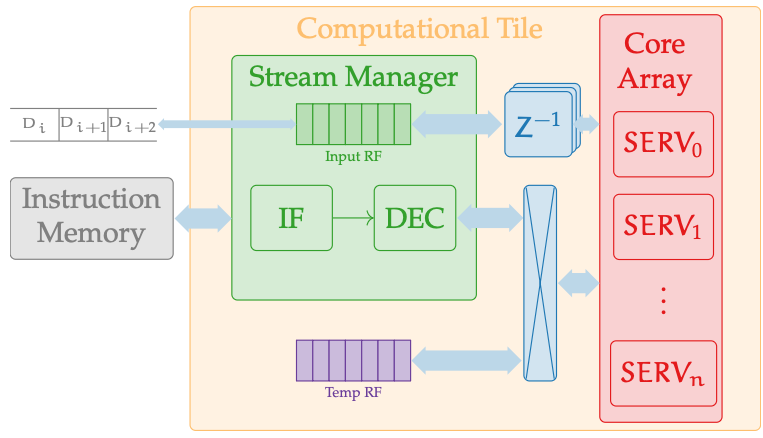
Architecture
Each tile has two tightly-coupled blocks:
- Stream Manager (front-end): routes incoming streams, schedules work (FCFS), and centralizes instruction fetch/decode for all cores.
- Core Array: many ultra-small RISC-V SERV cores (bit-serial) that execute the broadcast instruction stream under D-SIMD timing.
Programmability: keeping C/C++ without a memory stack
We chose RISC-V because its toolchain exists. The obstacle is that standard code assumes a stack and memory-based loads/stores. Instead of rewriting the compiler, we intercept compilation and rewrite: (1) stack-related function behavior at the IR level to be register-only, and (2) load/store instructions at the assembly level to map to register-file operations.
This preserves a familiar workflow for writing kernels in C/C++, but it also imposes constraints: large arrays and deep recursion must be redesigned.
What we demonstrated (preliminary results)
| Metric | What we observed |
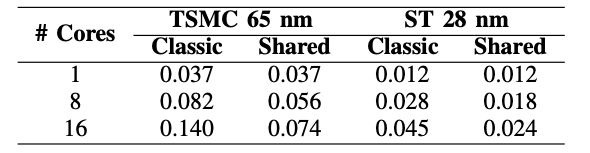
| ASIC tile area (16 cores) | 0.024 mm2 in 28 nm post-place-and-route; 0.074 mm2 in 65 nm. |
| Area benefit of shared fetch/decode | Up to ~45% area reduction vs. baseline SERV tiles withoutmutualization (16-core case). |
| Scalability | The shared-control approach becomes more advantageous as corecount increases (benefits beyond ~8 cores). |
Limitations (current)
- Register-only execution limits algorithms that rely on large state or buffers (e.g., large-N FFT without redesign).
- Bit-serial SERV cores trade latency for area; some applications may need a more parallel core variant (currently in debugging, nov. 2025).
- Full energy validation requires post-silicon measurement campaigns; current results emphasize feasibility and compactness.
What comes next
- Deeper toolchain support for the memoryless model (fewer manual constraints).
- Stronger verification at scale and improved critical paths for higher frequency.
- Dynamic switching between Batch / Convolutional / RoI modes.
- Benchmarking on real datasets: qubit readouts, ECG, radar pulses.
Reference: